AI engines don't invent your brand's identity — they assemble it from machine-readable sources they trust. Wikidata is the most powerful one you're actually allowed to edit. Here's why it matters for AI citations, and how to claim your entity.
How one Wikidata item travels into an AI answer
Ask ChatGPT, Gemini, or Google's AI Overviews "what is [your company]?" and something quietly decisive happens: the model doesn't reason your identity from scratch.
It pulls from a web of structured, machine-readable facts it has already learned to trust — and then phrases an answer. If your brand isn't clearly defined in that web, the model guesses. It mislabels your category, attributes the wrong founders, or skips you entirely in favor of a competitor it understands better.
For the last decade, search was a contest of keywords and links. That era is closing. The new contest is about entities — whether machines recognize your brand as a distinct, well-defined thing in the world, with a category, a history, and relationships to other entities.
And of all the sources that feed that machine understanding, one is uniquely accessible: you can edit it yourself, today, for free. It's called Wikidata.
01 From keywords to entities
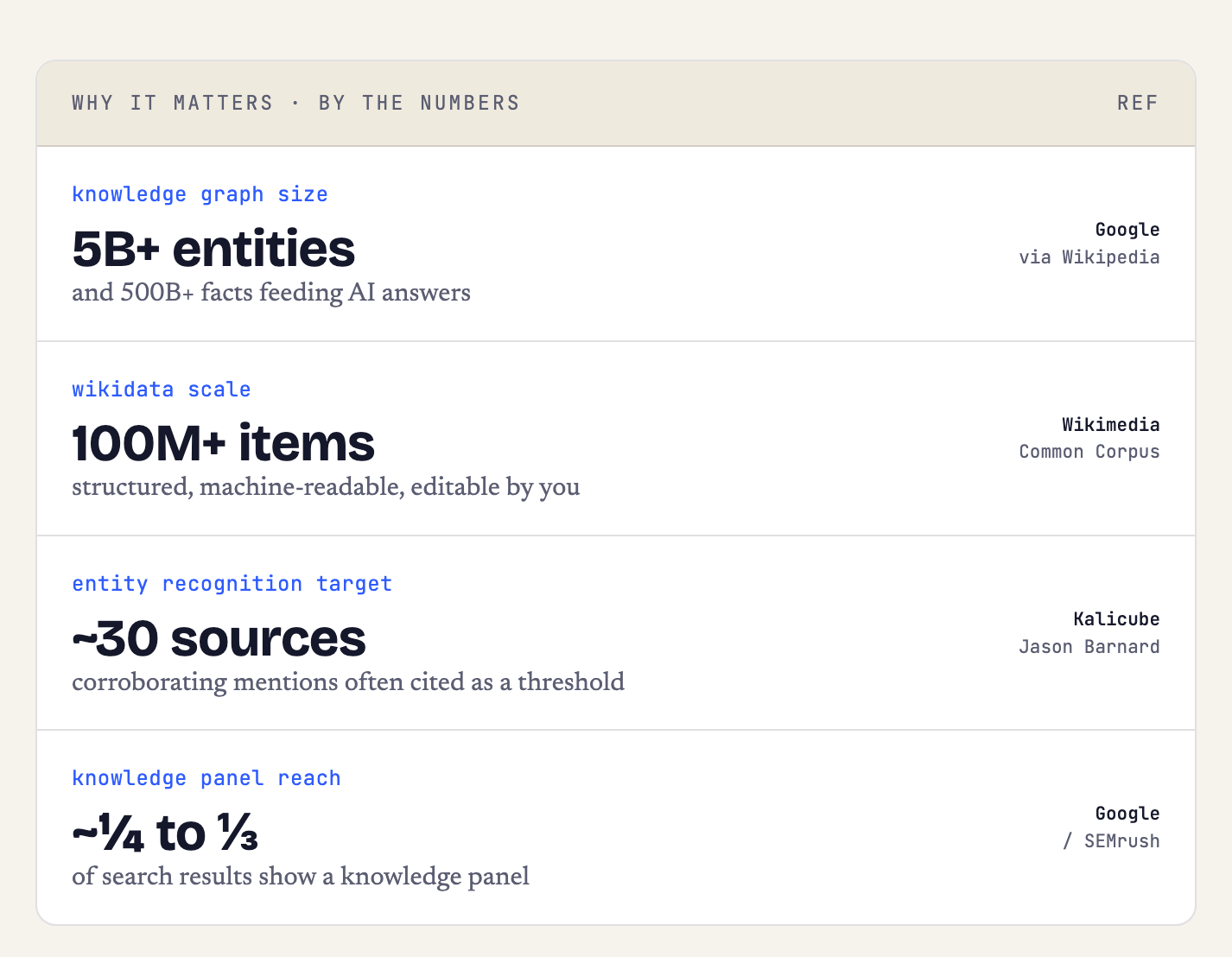
Google's Knowledge Graph is the database that sits underneath modern search — a structured map of people, places, companies, and the relationships between them. According to Google's own figures, it holds more than 5 billion entities and over 500 billion facts. It's the reason a search for "Amazon" can tell the difference between the company and the river: each is a node, connected to other nodes by defined relationships.
Here's why that matters more than ever. Google's AI products — AI Overviews, AI Mode, and Gemini — all draw on the Knowledge Graph to resolve entities, verify facts, and decide which brands deserve to be named in an AI-generated answer. As Ahrefs put it in their analysis of the graph, entity optimization has moved from a niche SEO tactic to a direct factor in whether your brand appears in AI-powered search at all. If the graph doesn't have a clean definition of your brand, the AI layer built on top of it has nothing solid to cite.
If the Knowledge Graph doesn't know what you are, the AI answer built on top of it has nothing to cite.
02 What Wikidata actually is
Wikidata is the structured-data backbone of the Wikimedia projects — the machine-readable counterpart to Wikipedia. Where Wikipedia stores prose, Wikidata stores statements: discrete, referenced facts like "instance of: software company" or "headquarters: Bengaluru." Launched in 2011 and maintained by a global community, it now holds more than 100 million items and several billion factual statements.
That structured format is exactly what machines want. A statement like "founded: 2015" needs no interpretation — it's already in the shape a knowledge graph or a language model can ingest directly. Google has used Wikidata for search disambiguation for years, and a significant portion of the Knowledge Graph is built from it. For brands, that creates a rare opening: instead of hoping Google correctly infers who you are by crawling your site, you can hand it the official schematic.
03 The citation chain
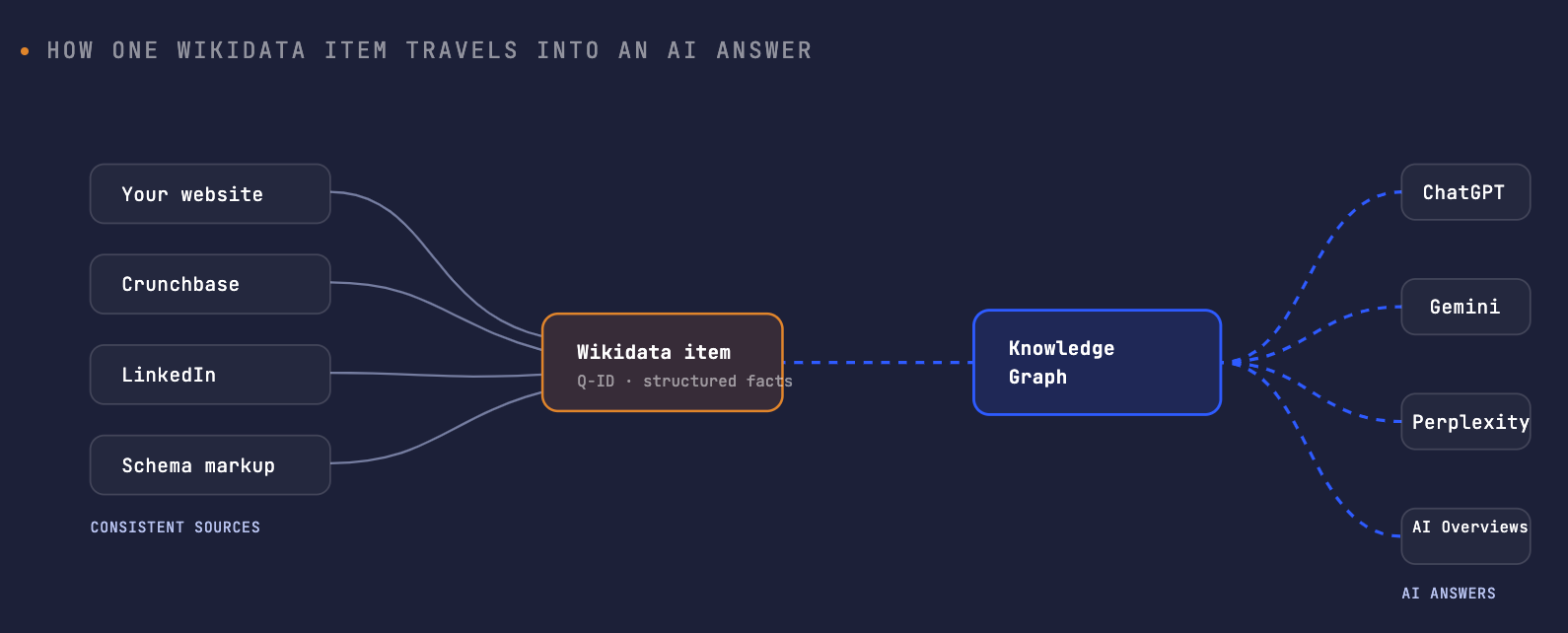
The reason a Wikidata entry punches so far above its weight is that it sits at the head of a chain. Update one clean, referenced item, and the effect propagates outward — into the Knowledge Graph, into Knowledge Panels, and into the AI answers built on those foundations. The diagram at the top of this post traces that path: consistent sources feed your Wikidata item, which feeds the Knowledge Graph, which feeds the answer a user actually reads.
Large language models don't query Google's proprietary graph directly during training. But the relationship is still real, in two ways. First, publicly available datasets like Wikidata are used to train and fine-tune models and to inject structured knowledge — so the facts you publish there can end up in a model's understanding. Second, retrieval-based systems like Perplexity and AI search prefer entities that are well-defined and structurally consistent. Either path rewards the same thing: a clean, corroborated entity.
04 Why it beats chasing a Wikipedia page
Most brands fixate on Wikipedia and hit a wall. Wikipedia's notability bar is high, its editors are openly hostile to self-editing, and a clumsy attempt can backfire publicly — when The North Face manipulated Wikipedia images, the stunt itself ended up documented on the company's own Wikipedia page.
Wikidata is a different proposition. Its bar is structural, not reputational: an item needs to refer to a clearly identifiable entity that can be described with serious, public references. A real, operating company with a website and a few external sources — Crunchbase, LinkedIn, Product Hunt, a press mention — generally clears it. Ahrefs goes as far as arguing that getting into Wikidata is as important as a Wikipedia page, and considerably more achievable. Conflict-of-interest editing is also permitted on Wikidata, provided everything you add is factual and neutrally sourced.
The one rule that protects you - Unreferenced company items are the ones that get nominated for deletion. Attach a citation to every factual statement you add. A neutral, well-sourced data item survives; a promotional, thinly-sourced one gets flagged.
05 How to get your brand on Wikidata
The whole process takes an afternoon once your references are lined up. Work through it in this order:
1) Line up 2–3 independent references first
Before you touch the editor, gather linkable sources that confirm your basic facts: official site, Crunchbase, Product Hunt, LinkedIn, any press. These become the references that protect your item from deletion.
2) Create the item
Log in at wikidata.org (not Wikipedia) and choose "Create a new Item."
Set the English label to your brand name and a short, lowercase, non-promotional description — e.g. "AI search visibility software platform." No articles, no taglines.
3) Add core statements, each with a reference
Build out the facts: instance of (P31) → business or software company, industry (P452), inception (P571), country (P17), headquarters (P159), official website (P856), and founded by (P112) where referenceable. Click "add reference" on each.
4) Stay scrupulously neutral
Structured facts only — no feature lists, no "leading platform." The positioning payoff is indirect: a clean factual node with a tight description becomes something the Knowledge Graph and AI engines can pull from.
5) Close the loop with schema
Once your item is live, grab its Q-ID and add it to your website's Organization schema in the sameAs array, alongside your social profiles. This creates a direct, machine-readable link between your site and your Knowledge Graph entity — telling Google exactly which node you are.
06 What to expect after it's live
Be honest with yourself about timelines. A Wikidata item does not instantly summon a Google Knowledge Panel — that still depends on Google connecting enough corroborating signals across the web, with practitioners often citing around 30 consistent sources as a working target. And associations already baked into a model's training data shift slowly, only really moving at the next model refresh.
But retrieval-grounded answers — AI Overviews, Perplexity, AI search — respond far faster, because they read the current web. The highest-leverage move is consistency: reuse the exact same description and category across your Wikidata item, your schema markup, your llms.txt, and your About page. When every source agrees, the machines stop guessing and start citing.