How To Fix Blocked Due to Access Forbidden (403) Error in Google Search Console
The 403 Forbidden error can occur for following reasons 1. Corrupt .htaccess file | 2. Incorrect file permissions | 3. Wrong IP address | 4. Faulty Plugins.

If you’ve ever come across the "Blocked Due to Access Forbidden (403)" error in Google Search Console, you know how frustrating it can be. This error means Googlebot is being denied access to certain pages on your website, potentially affecting your SEO. But don’t worry—there are ways to fix it and even prevent it from happening again. In this article, we’ll break down what this error is, why it occurs, and the steps you can take to resolve it.
Key Takeaways
- The 403 error in Google Search Console indicates that Googlebot is blocked from accessing certain pages on your site.
- Common causes include issues with your robots.txt file, server restrictions, or misconfigured plugins.
- You can identify affected pages using the Page Indexing report in Google Search Console.
- Fixing the error often involves updating server settings, adjusting robots.txt rules, or whitelisting Googlebot.
- Regularly monitoring your site and collaborating with developers can help prevent future 403 errors.
Understanding the Blocked Due to Access Forbidden (403) Error
What the 403 Error Means in Google Search Console
When you see the "Blocked Due to Access Forbidden (403)" error in Google Search Console, it simply means that Googlebot tried to access a page on your website but was denied. This happens when the server responds with a 403 HTTP status code, indicating that the crawler is not allowed to view the content. Think of it as Googlebot knocking on a door and being told, "No entry."
How Googlebot Interprets the 403 Status Code
Googlebot treats a 403 status code as a hard stop. This means it won't try to crawl the page again unless changes are made to permissions or settings. For Google, a 403 error signals that the page is intentionally restricted, even if that's not your intention. This can lead to indexing issues, especially for critical pages that should be visible in search results.
Common Misconceptions About the 403 Error
There are a few myths about the 403 error that are worth clearing up:
- "It only happens because of robots.txt." While robots.txt can block access, server settings, plugins, or even accidental misconfigurations can also cause this error.
- "Google will eventually fix it on its own." Nope. Unless you address the root cause, the error will persist in Google Search Console.
- "All 403 errors are bad." Not necessarily. Some pages, like admin dashboards or private content, are meant to be restricted.
A 403 error isn't always a problem, but when it affects pages that should be accessible to Googlebot, it can hurt your site's visibility. Taking action is key to keeping your site search-friendly.
Identifying Pages Affected by the 403 Error
Using the Page Indexing Report in Google Search Console
To locate pages impacted by the 403 error, start with the Page Indexing Report in Google Search Console. This report is found under the "Indexing" section in the left-hand menu. Once there, scroll down to see a detailed list of indexing issues flagged by Google. The "Blocked Due to Access Forbidden (403)" status will be clearly highlighted, helping you pinpoint problematic URLs quickly.
Exporting and Filtering Impacted URLs
Google Search Console allows you to export the list of affected URLs, which is especially handy for larger websites. Once exported, use a spreadsheet tool to filter and organize the data. Focus on URLs that are part of your sitemap or are otherwise critical to your site’s performance. This approach ensures you’re prioritizing the most important pages first.
Spotting High-Priority Pages for Fixing
Not all 403 errors are equal. Some pages might be intentionally restricted, while others could be vital for user navigation or SEO. To decide which ones to address first:
- Look for high-traffic pages that are blocked.
- Identify URLs included in your sitemap.
- Check if key landing pages or product pages are affected.
Pro Tip: Always double-check whether the restrictions on these pages are intentional or accidental before making changes.
For example, if your domain recently faced an SEO spam attack, some of these errors could stem from leftover misconfigurations. Addressing these promptly can help restore normal functionality.
If you are on the Indexly platform, this is how you can Verify the Error Is Correct & Accurate
We first need to verify whether the warning served in your page indexing report is correct and that we need to fix something.
To do this, you can go to the Indexly page inspection tab and enter the URL details to see if Indexly is displaying the same error. Inspection Page UI will look like this
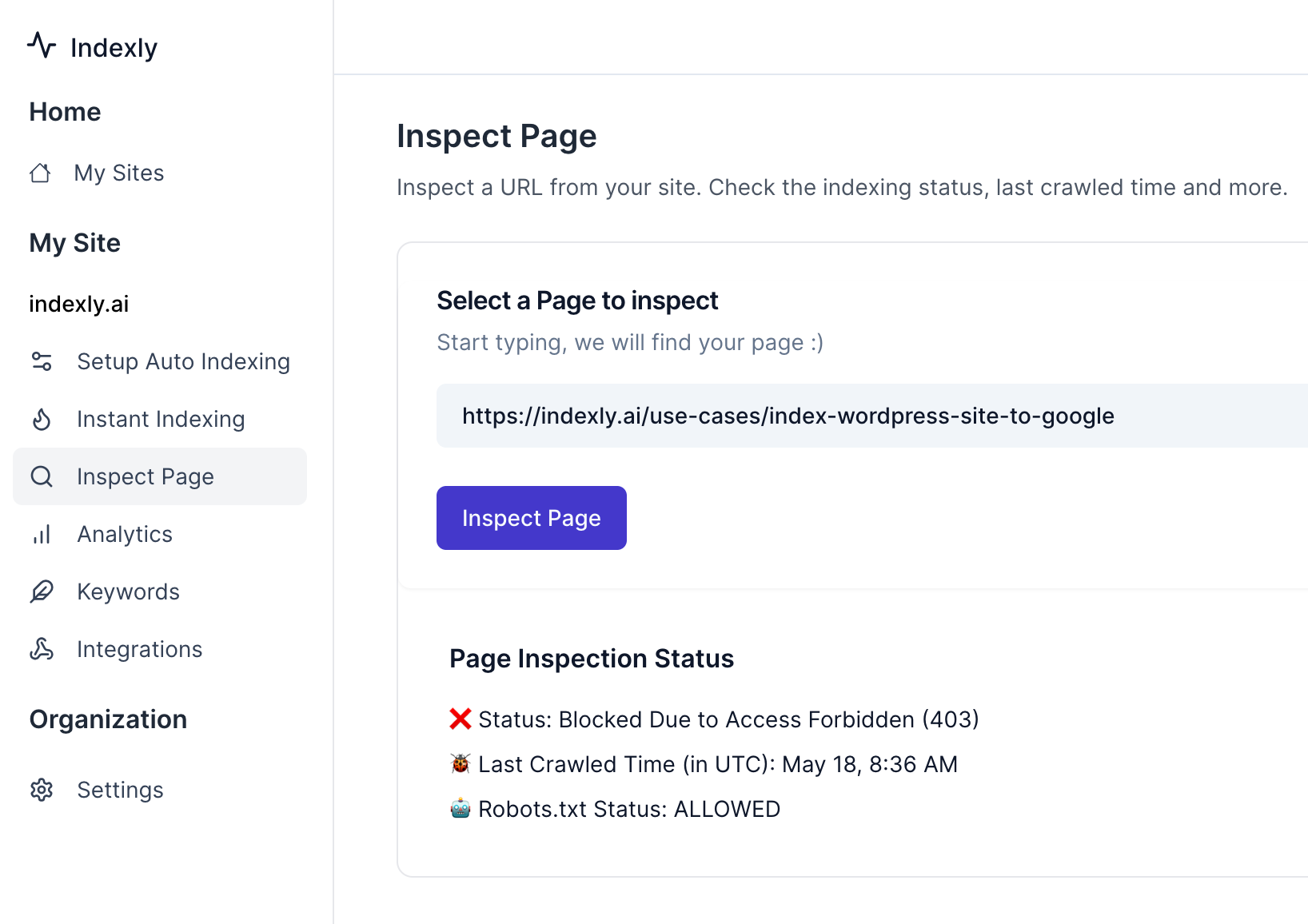
Common Causes of the Blocked Due to Access Forbidden (403) Error
Issues with Robots.txt File
The robots.txt file is like a set of instructions for search engine crawlers, telling them where they can and cannot go on your site. If this file has rules that block Googlebot from accessing certain parts of your website, it will result in a 403 error. Even a small misconfiguration here can block key pages from being crawled. Double-check for any "Disallow" directives that might unintentionally restrict search engines.
Server-Level Restrictions and IP Blocking
Sometimes, your server settings might be the culprit. Servers often block specific IP addresses as a security measure, but if Googlebot’s IP range is mistakenly blocked, it will trigger a 403 error. This can happen due to overly aggressive firewall rules or tools like Cloudflare's "bot fight mode," which might misidentify Googlebot as a threat. Learn more about Cloudflare settings to avoid accidental restrictions.
Authentication and Login Requirements
If parts of your site require login credentials to access content, Googlebot won't be able to pass through. For example, private forums, subscription-only content, or admin-only sections will throw a 403 error since Googlebot doesn’t have a username or password to log in.
CMS or Plugin Configuration Problems
Content management systems (CMS) like WordPress often come with plugins or built-in settings that block search engine crawlers. For instance, some plugins designed for security may restrict bots by default. Additionally, misconfigured settings might unintentionally prevent Googlebot from accessing certain pages or directories. Always review your CMS settings and plugin configurations.
Misconfigured .htaccess Files
The .htaccess file is a small yet powerful configuration file used by many websites. A single line of incorrect code here can block access to entire sections of your site. For example, if the file includes rules that deny access to certain user agents, Googlebot might be locked out. Review this file carefully for any unintended restrictions.
Steps to Resolve the 403 Error in Google Search Console
Checking and Updating Robots.txt Rules
The first step is to examine your robots.txt file. This file tells search engines which parts of your website they can or cannot crawl. Make sure Googlebot isn't being blocked unintentionally. Look for entries like Disallow: / or specific folders that might be preventing access. If needed, update the file to allow Googlebot access to the affected pages. Always save and re-upload the corrected file to your server.
Adjusting Server and Firewall Settings
Sometimes, server configurations or firewall rules can block Googlebot. Check your server logs to identify if Googlebot's requests are being denied. If you use a firewall like Cloudflare, review its settings to ensure Googlebot isn't being mistakenly flagged. Whitelisting Googlebot's IPs can often resolve this issue. Consult your hosting provider if you’re unsure how to access or modify these settings.
Whitelisting Googlebot in Security Plugins
If your site uses a CMS like WordPress, security plugins might block Googlebot thinking it's a threat. Go into your plugin settings and verify if Googlebot is listed as a blocked entity. Add it to the allowlist if necessary. This step is crucial for maintaining both security and accessibility.
Fixing Misconfigured .htaccess Files
The .htaccess file controls many aspects of your site's permissions. A misconfigured rule here can block Googlebot. Open the file and look for directives like Deny from all or specific IP blocks. Remove or adjust these as needed. Be cautious, though—this file is sensitive, and incorrect changes can break your site. Always back it up before editing.
Resolving 403 errors can feel tedious, but each fix brings you one step closer to better site visibility and performance in Google Search Console.
Preventing Future 403 Errors on Your Website
Regularly Reviewing Robots.txt and Server Settings
A proactive approach to managing your website's accessibility can save you from the headache of recurring 403 errors. Start by reviewing your robots.txt file periodically. Ensure that it doesn’t unintentionally block Googlebot or other essential crawlers. Similarly, check server settings to confirm there aren’t any restrictive rules or outdated configurations that could result in access issues.
Key steps to follow:
- Open and inspect your robots.txt file for any "Disallow" directives that might block critical pages.
- Test the file in Google Search Console to ensure it behaves as expected.
- Coordinate with your hosting provider to verify server-level configurations.
Monitoring Google Search Console for New Errors
Google Search Console is your best friend when it comes to spotting and addressing errors early. Make it a habit to check the "Page Indexing" report weekly. Any "Blocked due to access forbidden (403)" errors should be addressed promptly.
- Set up email alerts in Google Search Console for real-time notifications.
- Use the "Inspect URL" tool to test problematic pages and identify the root cause.
- After fixing issues, monitor the "Validation" process to ensure Googlebot can re-crawl the pages successfully.
Collaborating with Developers for Long-Term Solutions
Sometimes, the root causes of 403 errors require technical expertise. Collaborating closely with your development team ensures that such issues are addressed at their core. Whether it’s a misconfigured plugin, a problematic .htaccess file, or a server-side restriction, developers can implement sustainable fixes.
"Preventing 403 errors is not just about quick fixes; it's about creating a system where such errors are less likely to occur in the first place."
Here’s what you can do:
- Conduct quarterly audits of your website’s security and access settings.
- Document all changes made to the site’s infrastructure to avoid accidental misconfigurations.
- Ensure that your web server software is always up-to-date to minimize vulnerabilities.
By staying vigilant and maintaining a system of regular checks and balances, you can significantly reduce the likelihood of 403 errors disrupting your site’s performance.
When to Leave 403 Errors Unresolved
Understanding Intentional Restrictions
Sometimes, a 403 error is exactly what you want. For example, if you’ve got admin pages, internal directories, or sensitive files on your site, you probably don’t want them showing up in search results. In these cases, the 403 error is doing its job. It’s keeping Googlebot and other crawlers out of places they shouldn’t be. Just make sure these URLs are also blocked in your robots.txt file to avoid unnecessary crawling attempts.
Handling Sensitive or Private Content
Not all content on your site is meant for public eyes. Things like user profiles, payment portals, or internal tools often require login credentials or other forms of authentication. If these pages trigger 403 errors for Googlebot, that’s fine. They’re private for a reason. Just double-check that these restrictions are intentional and not the result of a misconfiguration.
Using Robots.txt to Manage Restricted Pages
If you know certain pages should remain off-limits, it’s a good idea to explicitly disallow them in your robots.txt file. This way, you’re telling search engines upfront not to bother crawling these areas. Here’s a quick example of how you might set this up:
User-agent: *
Disallow: /admin/
Disallow: /private/
This simple step can prevent unnecessary 403 errors from popping up in Google Search Console.
Remember, not every error needs fixing. If a 403 error aligns with your site’s goals and security policies, it’s better to leave it as is. Trying to "fix" these errors could actually expose sensitive information or create other issues.
Wrapping It Up
Dealing with a "Blocked Due to Access Forbidden (403)" error in Google Search Console can feel like a headache, but it’s definitely fixable. The key is to figure out what’s causing the block—whether it’s your server settings, a misconfigured .htaccess file, or even a plugin—and address it step by step. Once you’ve made the necessary adjustments, don’t forget to test your URLs in Search Console to make sure everything’s working as it should. Keep an eye on things for a few days to ensure the issue doesn’t pop up again. And remember, not every 403 error needs fixing—some pages are meant to stay private. Just focus on the ones that matter for your site’s visibility. With a little patience and troubleshooting, you’ll have your site back on track in no time.
Frequently Asked Questions
What does the 403 error mean in Google Search Console?
The 403 error in Google Search Console means that Googlebot tried to access a page on your website but was denied. This happens when the server returns a '403 Forbidden' status, signaling that the content is restricted.
How can I identify which pages are affected by the 403 error?
You can find affected pages by checking the Page Indexing report in Google Search Console. This report lists all URLs that are blocked due to access forbidden errors.
What are the common causes of the 403 error?
The 403 error can be caused by issues like incorrect rules in the robots.txt file, server settings blocking Googlebot, login requirements, or misconfigurations in CMS or plugins.
How can I fix the 403 error in Google Search Console?
To fix the error, check your robots.txt file, server settings, and .htaccess file for restrictions. Ensure Googlebot is whitelisted in security plugins and adjust any misconfigured settings.
Is it necessary to fix all 403 errors?
Not always. If the pages are intentionally restricted, like private or sensitive content, you may not need to fix them. However, public and important pages should be addressed to improve SEO.
How can I prevent 403 errors in the future?
Regularly review your robots.txt file and server settings, monitor Google Search Console for new errors, and collaborate with developers to ensure long-term solutions are in place.Blocked due to access forbidden (403) is a Google Search Console status. It means that some of your pages aren’t indexed because your website denied Googlebot access to them.
To crawl a page, Google must behave similarly to the user’s browser. Googlebot sends a request regarding the URL to your server. Servers respond to such requests with HTTP status codes, which tell browsers and crawlers if and how they can access the contents of that URL. 403 error happens when Googlebot doesn't get access to your web pages.
This isn’t typical, so this status could be a signal that your website requires a technical review.
What is the meaning of the 403 Forbidden Error?
The HTTP status code '403 Forbidden — you lack permission to access this resource appears when a web server acknowledges a user's request but cannot grant further access. This error commonly arises due to insufficient permissions or authentication credentials on the server side.
What triggers the 403 Forbidden Error?
HTTP 403 Forbidden errors typically stem from a client-side configuration issue, making them usually resolvable independently. One prevalent cause of a 403 Forbidden error is the configuration settings for a particular folder or file. These settings dictate which users can read, write, or execute that folder or file.
The two most likely causes of the 403 Forbidden Error are:
- Corrupt .htaccess file
- Incorrect file permissions
- Wrong IP address
- Faulty Plugins
It’s also possible that you’re seeing the error because of an issue with a plugin on your site. In this article, we’ll show you how to troubleshoot these potential issues.



